
邮箱:support@zcecs.com
地址:北京市西城区南滨河路27号贵都国际中心A座1111室
1)SLA的颗粒有多少维度?
2)SLA与设计
3)SLA与成本
SLA的颗粒度
SLA:Service level agreement,服务水平协议/约定,一般会通过服务的受影响范围、受影响时间定义服务能保障的水平,并有相应的惩罚措施,以免仅仅是一纸空文的约束。另一方面数据中心综合服务往往提供多项服务,其SLA也可以根据服务种类进行划分。
1)受影响范围
①一般可以按照同一客户或者应用侧感知同类服务受影响的比例来约定SLA的故障或者事故的定义。
对于云服务及IDC等有较合理计费单位,可以按照受影响的同类业务或者服务计费单位比例来计算,比如受影响的流量或者服务器数量占用总计费数量的比例,或者机柜数/总租用机柜数。
对于对服务质量有较高要求的EDC或者自营业务等内部计费或者结算单位可能不够详尽,可以参考IDC或者云服务商们提供的计算方式。
②也可以按照同一客户或者应用侧总服务受影响的比例来约定SLA的故障或者事故的定义。
总服务与同类服务的区别在于,不再划分上层业务系统,只简单划分核心与非核心或者生产与非生产两大类服务,以受影响的基础承载资源比例计算和定义其故障与事故。
③对服务提供商自身的内部管理而言,往往跨越了多客户或者应用侧多部门多终端,按照其业务类型比如IDC,IAAS,PAAS,SAAS,分别计算其承载的基础资源或者计费单位受影响的比例,并以此来定义故障与事故。
④由于行业蓬勃发展,竞争激励,一般受影响比例不超过10%,即确定为需要赔偿或者处罚等启动追责之事故。
2)受影响时间:
①统计周期按年计算;
②统计周期按季度计算;
③统计周期按月度计算;
④统计周期按天计算;
⑤统计周期按小时计算;
⑥统计周期按S计算;
a:受影响时间,按可靠性计算;
b:受影响时间,按照s计算;
b与a可按下式换算:
b=N*(1-a);
N为以秒S计算的统计周期时间。
3)服务种类:
①网络服务
除三大运营商外,及部分中立多点间专营直联网络外,网络服务往往由第三方提供,其服务的水平保障较依赖运营商和选择的路由,因此往往SLA中会不约定此项,或者会单独约定。
②电力供应服务
③其他环境等基础服务
比如温湿度控制等,或者改造及日常维护等各种辅助服务。往往以服务器宕机为事故标准。
④IAAS
⑤PAAS
⑥SAAS
④-⑥往往以客户或者终端或者应用侧感知的由提供服务引起的故障为事故标准。
4)惩罚措施
①补偿受影响时间的倍数
②补偿受影响范围的倍数
③补偿上限
④补偿相关损失
设计与SLA
1)SLA的设计目标将根据以下综合确定:
①潜在客户的要求
②行业标准
③服务价格与利润预期
④实现SLA的成本
2)SLA设计与计算:
①SLA设计时,罚则代表的是违反SLA的代价。故障与事故、服务中断的定义往往均根据行业标准和惯例,进行设计,并根据潜在或者客户市场反馈进行一定的差异化设计。而实现基础SLA的成本,往往需要借助可靠性这样一个量化指标。
②SLA中的关键设施或者服务的可靠性,我们在前文《[基础]:MTBF与可靠性》中重点提示大家,要和MTBF区别开来。MTBF(平均无故障工作时间)是统计意义上的可靠性与我们要实现的可靠性完全不是一个概念。
③对于经过优秀的专业设计、建设,并有专业维护和运行团队保障的专业运营级数据中心或者相应的云服务,在一个运营期内数据中心的故障概率实际上已经通过专业设计、建设、测试与验收去除了浴缸曲线的前半段,通过科学合理的设备全生命周期预测及预防性维护与更新,抚平了浴缸曲线的后半段。基本可以认为故障概率是平均偶发的,其概率密度曲线可以认为是常数。
④在数据中心基础设施层面,单个系统或者设备往往是由多个元器件构成,其可靠性应按照单个元器件分别计算后,根据可靠性模型,依据相应的串并联关系进行可靠性的综合计算。
3)SLA常见设计优化策略:
①通过可靠性计算明确短板所在;
②通过经济性计算明确刀刃所在;
③权衡提高SLA的成本与收益;
④权衡降低SLA的代价与风险。
4)虚拟案例:(纯属虚构,如有雷同,实属巧合)
项目背景:汕尾,某港资背景房地产开发商并未撤向欧洲而是全部转向大陆。从将军澳架设海底光缆直连汕尾,通过IPV9联向全国核心节点。计划建立相当于1000万通用标准计算与存储节点覆盖IDC、IAAS、PAAS、SAAS全生态的基础设施。
项目SLA需求:
①满足现在及未来多种客户的需求;
②最大程度上创造利润。
项目SLA设计目标分级:
①可靠性
Ⅰ级,R>99.99%
Ⅱ级,R>99.9%
Ⅲ级,R>99%
②赔偿时间
Ⅰ级,1000倍故障时间补偿,且不超过合同时间
Ⅱ级,100倍故障时间补偿,且不超过合同时间
Ⅲ级,10倍故障时间补偿,且不超过合同时间
Ⅳ级,1倍故障时间补偿
③赔偿比例
Ⅰ级,1000倍故障区域补偿,且不超过服务区域
Ⅱ级,100倍故障区域补偿,且不超过服务区域
Ⅲ级,10倍故障区域补偿,且不超过服务区域
Ⅳ级,1倍故障区域补偿
④计划维护时间
Ⅰ级,计划维护时间≤0h
Ⅱ级,计划维护时间≤7.2h
Ⅲ级,计划维护时间≤72h
SLA设计与计算关键点:
①SLA设计时应注意不要忽略人力、物资库存、财务等硬件之外的软件设计。
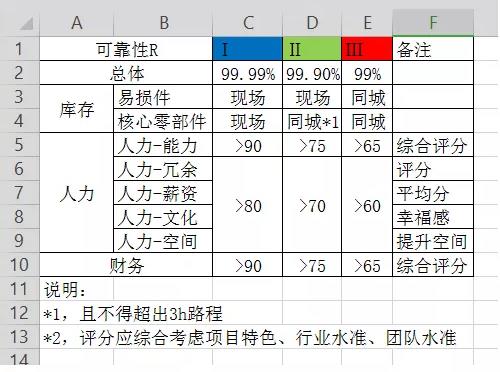
表1-总体可靠性分级
②根据前文《[基础]:MTBF与可靠性》,当故障概率λ2为常数时:
预期寿命T=2MTBF;λ2=1/2MTBF;
系统无故障运行时间等于MTBF的可靠性,
R(MTBF)=50%;
系统无故障运行时间等于MTBF/100的可靠性,
R(MTBF/100)=99%
当采用1+1冗余时,MTBF=10万h,第一年无故障运行的可靠性仅达到Ⅲ级;前五年无故障运行的概率仅有95.2%。附表2为部分常见冗余和MTBF下,系统的可靠性计算结果。
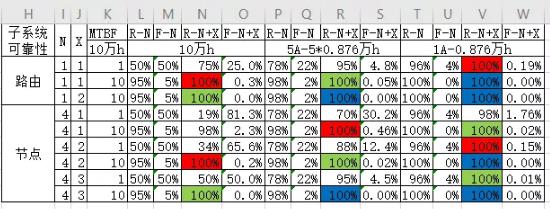
表2-MTBF与可靠性-专业偶发类
说明:
*1,R-N,分析单元自身的可靠性;
*2,F-N,分析单元自身的故障率,1-R-N;
*3,R-N+X,含X冗余后的分析单元的可靠性,
∑C(N+X,I)*R-N^I*F-N^(N+X-I),I从N到N+X;
*4,红色的说明计算单元在指定时间内无故障运行的可靠性超过Ⅲ类,绿色Ⅱ类,蓝色Ⅰ类;
*5,均为100%却显示不同颜色主要是显示位数的问题,可通过故障率反算其可靠性。
③根据前文《[基础]:MTBF与可靠性》,当单元可靠性服从e^-λt时:
λ=1/MTBF;
系统无故障运行时间等于MTBF的可靠性,
R(MTBF)=36.79%;
系统无故障运行时间等于MTBF/100的可靠性,
R(MTBF/100)=99%
当采用1+1冗余时,MTBF=10万h,第一年无故障运行的可靠性仅达到Ⅲ类;前五年无故障运行的概率仅有87.4%。附表3为部分常见冗余和MTBF下,系统的可靠性计算结果。
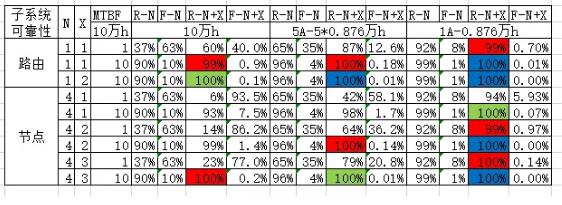
表3-MTBF与可靠性-电器及控制类
④是不是SLA承诺R>99%,该单元就一定要可靠性达到99%呢?并不是,主要看违反的代价和遵守的成本。遵守的成本按照可靠性计算增量冗余的增量成本,赔偿成本要看SLA中设计的赔偿时间与赔偿区域比例及增量冗余前的可靠性期望。
SLA与成本
无论系统或者节点的可靠性服从哪种规律,依据MTBF的定义可知,MTBF实际上是系统寿命/正常运行时间的期望。考虑企业盈利,其SLA等级设置应满足下式:
(1-①可靠性)*②赔偿时间*③赔偿比例<A/KB;
式中:
①取可靠性设计数值,②③取赔偿倍数;
A为服务利润率;
K为可靠性风险偏离期望的倍数;
B为愿意承担的风险系数,B=1保本,B=2愿意承担利润亏掉一半,B=0.5愿意承担赔偿后亏损率达到原服务利润率。
如果运营方资金雄厚,可以承担和抵抗风险波动和赔偿损失而不影响运营和决策能力,且其为新入行或者跨界进入DC行业。可以按照下式配置其SLA等级:
K=1;
而一般企业,专业运营K<2,合格运营K<3。
SLA等级设计完成后,其违反代价即可计算得出。而其成本,设计实现路径,却需要进行经济分析:
①设计高可靠性架构,一次性投入大,要求整个寿命周期内可靠性达标;
②设计典型可靠性架构,当可靠性随着时间可能低于设计要求时,补充专业维护方面的投入,提升可靠性至达标水准。
比如某核心设备,MTBF=100万h与10万h的价格差a=10%,考虑资金年化通胀率b=3.5%,主航道收益率c=10%,d=10,十年经济寿命,其可靠性应高出e=1.90%,才达到方案①②平衡的临界点。
上述临界点可按下式计算:
x=(1+b)*(1+c);
e=a*(x-1)*x^d/(x^d-1);
精确计算也可按月重新输入bcd,得出月可靠性提升临界点e。
继续上例,假设该设备故障服从表2类专业偶发类故障,且平均冗余近视为4+1,则第一年设计可靠性提升1.74%,五年年均算术可靠性提升5.949%,十年年均算术可靠性提升7.080%,是否选择高可靠方案看风险偏好及增量投资可行性。(相对于加权平均可靠性,算术平均可靠性忽略了赔偿期望所带来的资金提早投入的资金时间收益。)
假设该设备故障服从表3类专业偶发类故障,且平均冗余近视为4+1,则第一年设计可靠性提升5.86%,五年年均算术可靠性提升11.274%,十年年均算术可靠性提升8.404%,是否选择高可靠方案看风险偏好及增量投资可行性。
软件定义与SLA
1)KPI与SLA
与前期介绍的PUE、SUE不同,SLA数字化的是可靠性、成本、风险及相关的决策关系链,是其他一切指标的基础性指标。
①应分别记录上到系统,下到节点设备、路由,甚至是零部件的故障次数时间间隔、维护价格、时间等对内的成本信息,以便分析和使用。
②应注意事故次数、影响范围、赔偿金额、赔偿面积等SLA执行数据的收集。
③应注意SLA设计与决策数据的收集。
④应注意跨数据中心数值的收集与记录。
①SLA的分析在设计阶段,主要是关注其全行业或者某个垂直客户领域的平均参考水平,及其对销售、架构及设备可靠性的约束,对成本、收益及风险在建设、销售两端的权衡;
②在运行阶段对SLA的分析,主要是对设备及系统全寿命周期管控及更替的合理性进行评价。对基于其他KPI的优化,进行所涉的评价与优化;
③应关注终端市场的潜移默化的变化,并进行相关的投入与改造,以便经济的前提下优化SLA满足最新市场需求;
④将复杂的可靠性、风险、成本、收益等量化,便于软件定义与系统智能化及智慧化升级。

